0. 引言
近年来,由于全球气候变暖,极端气温事件发生频率变高,强度更大,给社会经济带来了严重的损失[1]。为了更好的掌握气候演变规律,为社会生产生活提供帮助,对极端气温事件的发生、发展及其变化规律的问题的研究已经成为气象以及GIS领域的研究热点[2][3]。
现有的对极端气温事件的研究大多采用基于统计学的方法[4][5],但目前空间数据获取技术的进步使得空间数据日益丰富,超出了传统方法的分析能力,简单的统计学分析已经不能满足需要[6]。因此本文结合传统的数据挖掘技术与地理空间分析方法,设计了一种新的空间关联模式挖掘方法,用于有效识别极端气温事件时空数据集中存在的多种形式的关联模式。
本文的研究通过对全国772个气象台站1961年至2005年极端气温事件时空数据集进行预处理,利用空间数据挖掘的方法获取关联模式,并借助地理空间分析的方法进行进一步的空间分析,探究极端天气在空间上的发生规律。
1. 研究现状
1.1 极端气温事件的研究现状
极端气温事件的提取方法很多,有按照绝对阈值的方法定义极端气候,但目前国际上多采用相对阈值法代替传统的绝对阈值法,在气候极值变化研究中多采用百分位阈值法作为极端值的阈值[7]。IPCC第三次和第四次评估报告在对极端气温时间定义时都采用国际上使用最多的百分位定义法[8],即对研究时间内每个测站的逐月(日)最高(低)气温资料按照降序排列,将某一百分位值定义为该测站该年的极端高(低)温阈值,可根据实际研究的需要以及时间序列长度的不同选择不同百分位等级。
目前关于极端气温事件的研究主要集中在局部区域时空变化特征[9、10]分析、某一独立站点的时间序列分析[11]、集群性分析[7、12]。我国学者对极端气温事件的时空分析研究已有较长历史,取得了大量成果[9-11、13-16]。在局部区域时空变化特征的研究上,有对于秦岭南北地区50来年平均气温、年极端最高、最低气温的时空变化特征分析[10],对山东省降水极值的统计特征和变化趋势的分析等[9];在关于独立站点的时间序列分析的研究上,有对于北京极端气温变化特征与对城市化进程的影响的分析[11]等;另外还有关于极端气温事件的群发性规律的研究[7],定义了K阶最近邻距离丛集点提取算法并对极端气温和降水进行空间分布特征现实的分析。
但是现有的研究多使用统计学方法,建立统计模型进行定量分析,或针对某一独立站点进行时间序列分析,不能满足气温现象作为地理区域化变量存在空间关联的特性,缺少针对站点之间的相互影响与关联的分析。
1.2 空间关联规则挖掘的研究现状
空间关联规则是指空间目标间相邻、相连、共生、包含等关联规则,它是从空间数据库、空间数据仓库发现的主要知识类型之一[6]。自从K.Koperski于20世纪90年代将传统关联规则引入空间数据挖掘领域,并给出空间关联规则的相关概念、挖掘过程和挖掘算法[17]以来,学者们从概念、测度和挖掘算法等方面对空间关联挖掘进行了深入的研究。
已有的空间关联模式挖掘方法大体分成两类:基于空间统计分析的和基于数据挖掘的[18]。现有的相关挖掘算法[19-25]大多是基于对空间数据库的优化和统计学的相关知识,将属于空间关联规则的挖掘问题转化为已经研究比较成熟的传统的属性关联规则挖掘问题,主要关注的是如何解决空间数据库自身海量性、多维性的特点所带来的问题,如何改进传统的挖掘算法,尽可能的提高其在空间数据挖掘上的效率,具有代表性的算法有借助谓词法[23]和基于概念格法[24-25]。传统的挖掘思路为“先数据清理,再知识发现”[26],即先扫描空间数据库,建立所有空间对象的集合,组织成一个关系型事物数据库,然后再进行空间关联规则挖掘。然而,这些算法在用于挖掘空间关联规则时,存在以下局限性:①空间数据具有空间自相关性。研究表明,数据的空间自相关性对空间关联规则的挖掘有很大的作用,而传统的空间关联规则挖掘,一般是使用属性关联规则的挖掘算法,对空间数据进行泛化处理[27],这不仅不能准确反映实际数据的空间关联情况,而且大大降低了挖掘的效率;②传统算法多是基于统计学的算法,在将空间问题非空间化时,是对GIS数据库进行重新整理的过程,必然会丢失其空间特征,损失信息,影响挖掘结果[23];③传统算法先创建空间事务,再依次对其进行分析或挖掘的方式并不能有效的挖掘出含有多种内容的空间关联规则,在挖掘成本、挖掘效率和挖掘精度等方面都存在很多问题,导致大量的空间知识尚未被挖掘出来。
因此,本文结合传统关联规则挖掘技术和地理空间分析方法,设计了一种新的空间关联模式挖掘方法,它基于“先挖掘再分析”的思维模式,首先用传统的数据挖掘技术对时空数据进行预处理,找出潜在频繁的空间关联模式;然后再借助地理空间数据分析的方法对挖掘所得的关联规则进行空间关联性分析,这种算法可克服传统算法存在的部分缺陷,有效的挖掘出时空数据集中存在的多种关联模式。
2. 极端气温事件的数据描述
2.1 极端气温事件的提取
从中国气象科学数据共享服务网获取全国772个台站信息及相关气象数据,数据库包含属性、空间、和时间三种类型的数据,时间区间为1951年01月01日至2005年12月31日,时间分辨率为日值;这些台站位于西经73.66E至东经135.08E、北纬53.52N至南纬4.00N范围内。总的来说,数据的可靠性较高,完整性较好,但是通过对原始数据集分析发现,部分台站出现了迁站、撤站等现象,且50年代的台站信息及气象数据缺失较多,因此最终筛选得到拟研究台站739个(空间分布如图1所示),时间范围选定为1961年01月01日至2005年12月31日,一定程度上减弱了台站信息缺失、台站迁移、起始年份不统一等偶然误差所带来的影响。
图2:河南信阳1961年至2005年7—9月份均温频数分布示意图
(Fig.2 monthly average temperature frequency distribution diagram
about XinYang , HeNan from July to September(1961—2005))
借助各气象台站的数据说明,对近45年内的日均温原始气象数据集进行筛选,去除数据缺失严重或明显错误较多的台站,确定待研究台站及时间区间,设计vba程序,计算月均温及极端气温事件阈值,获得数据挖掘的原始事务集。该数据集以全国范围内,各月份发生极端气温事件的站点为一条记录,共包含540条,其中1993年4月在全国无极端气温事件发生。
2.2 极端气温事件的时空分布模式
依据上节的极端气温事件数据集,采用统计学方法对所得极端气温事件发生的时间信息进行处理,结果如图3所示。
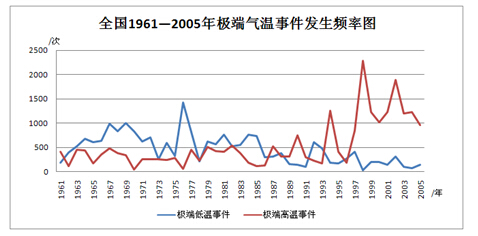
图3:全国1961-2005年极端气温事件发生频率图
(Fig.3 1961-2005 extreme temperature events frequency plot)
分析图3可知,从1961-2005年全国极端低温、高温事件发生频率的规律差异很大。极端低温事件以1976年为界,总体呈现一个先升后降的趋势,其中在1957年和1976年出现突变峰值。极端高温事件总体呈现上升趋势,以1993年为界,之前基本平稳,之后增长迅速,尤其是1994、1998、2002年出现三个峰值。
将统计学和可视化分析技术相结合,借助ArcGIS软件,对极端气温事件发生的空间信息主要进行如下两步处理:①以所研究时间范围内各台站极端高(低)温事件累计发生次数为第三维,采用线性半变异模型,以12个邻近点为搜索半径,进行普通克里金插值,并对插值所得结果采用按掩膜提取法进行提取分析;②为了更方便分析极端高(低)温事件的发生的空间分布规律,改善视觉感受效果,对插值所得的连续结果采用分级处理的方式表达,由于发生次数的范围为0—50,分六级即可精确表达,1961-2005全国气象台站极端气温事件累计次数结果空间分布图如图4和图5。
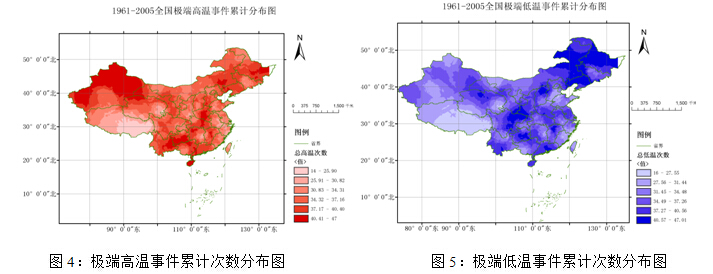
(Fig.4 Cumulative frequency distribution of extreme high temperature events map)
(Fig.5 Cumulative frequency distribution of extreme low temperature events map)
由图4可以看出,在全国范围内,每个台站累计发生极端高温次数差异很大,新疆、四川、广西、广东是极端高温分布集中的区域,沿海地区、青藏地区、内蒙等地高温发生频次较少。由图5可以看出,在全国范围内,每个台站累计发生极端高温次数差异很大,东北与内蒙古北部、川陕甘交界处是两个极端低温事件发生的集中区域,西藏、新疆、沿海地区发生极端低温的频次较低。
3. 极端气温事件的空间关联模式
本小节分为“空间关联模式提取”和“关联模式的空间分析”两部分内容。首先选取数据挖掘算法,从极端气温事件数据集中提取空间关联模式;然后借助地理空间数据分析的方法与ArcGIS可视化的技术对已识别的空间关联模式进行分析,得出空间关联规则的若干规律,包括其空间分布模式、空间距离关系、空间邻近关系、空间方位关系等。
3.1 关联模式提取
数据挖掘中,关键的问题在于支持度和置信度阈值的选取。支持度min_sup是模式为真的任务相关的元组(或事务)所占的百分比,用于衡量模式的潜在有用性;置信度min_conf则用于度量所发现模式的准确性或可靠性;同时满足用户定义的最小置信度阈值和最小支持度阈值的关联规则称为强关联规则,并认为是有趣的[28]。阈值的设置将直接影响挖掘结果的数量和质量,合适的阈值可以保证其所得关联规则的准确性、有趣性和科学性,保证算法挖掘结果的质量,因此需要根据数据集的内部特征进行合理设置,一般通过实验或经验选取适当的阈值。本次实验最终极端高温事件选取支持度为7%,置信度阈值为95%,极端低温事件选取支持度为6%,置信度阈值为95%。
实验选用FP-growth算法进行挖掘,其基本的思想是:①扫描极端气温事件数据集,获取所有频繁项及其出现频率,删除频率小于预先给定的最小支持度min_sup的项,构造频繁模式树FP-tree;②遍历整棵树获取满足最小置信度min_conf的关联规则。
FP-growth算法能有效克服传统Apriori算法的固有缺陷——需要产生大量候选项集和重复地扫描数据库,它只需要扫描2次数据库:第一次得到频繁1-项集;第二次扫描则是过滤频繁1-项集数据库中的非频繁项,同时生成FP-tree。本实验中,原始事物集为历年各月发生极端高(低)温事件的站点编码数据集,所挖掘关联规则是发生极端高(低)温事件的站点间的空间关联规则,为一元关系,因此采用FP-growth算法可以正确、有效的获取目标关联模式[28][29]。具体过程及原理如下[28][30]:
(1)根据事务数据库D,不断实验至选到满足条件的支持度min_sup,然后建立FP-tree;
(2)如果(FP.tree为简单路径)路径上支持度计数大于等于min_sup的节点任意组合,则得到所需的频繁模式;否则初始化最大频繁模式集合为空;
(3)按照支持频率升序,以每个l一频繁项为后缀,调用挖掘算法挖掘最大频繁模式集;
(4)根据最大频繁模式集合中最大频繁模式,输出全部的频繁模式。
借助FP-tree关联规则挖掘算法[32]所得关联规则的形式如表1所示例,以{吉林长春、辽宁开源}-{吉林四平}100%为例,从1961年1月至2005年12月这段期间,当吉林长春和辽宁开源都发生极端高温事件时,吉林四平有100%的可能性会发生极端高温事件,其余同理。
表1 FP-growth算法产生的部分高温关联规则(支持度阈值7%,置信度阈值95%,共产生65项)
(Tab.1 parts of extreme high temperature association rules generated by
FP-growth algorithm)

3.2 关联模式的空间分析
挖掘获得潜在的空间关联规则后,借助地理空间数据分析的方法与ArcGIS可视化的技术对已识别的空间关联规则的前件和后件进行空间分布、空间邻近、空间距离等分析,我们可以发现如下规律:
① 空间聚集性
所得空间关联模式中涉及的区域在空间上具有明显的聚集性。主要集中在东北平原和长江中下游地区,而整个西部地区都没有发现强关联模式;这些台站大多沿海或沿长江密集分布,较为集中,是否存在关联性与彼此之间的地理条件是否相似有着极大的关系。
极端低温事件涉及的区域主要为新疆和华中区两个区域,且在每一个小区域内也具有明显的空间集聚性;极端高温事件涉及的区域主要为华中区和东北区两个区域,其他地区出现强关联规则的频率相比之下则特别低,而且在华中地区,关联规则涉及的台站又明显集聚在三个小区域,如图6、图7所示。(其中,白色符号表示关联规则中的前件台站,黑色符号表示关联规则中的后件台站,黄色符号则表示在关联规则中既有作为前件出现也有作为后件出现的台站。)
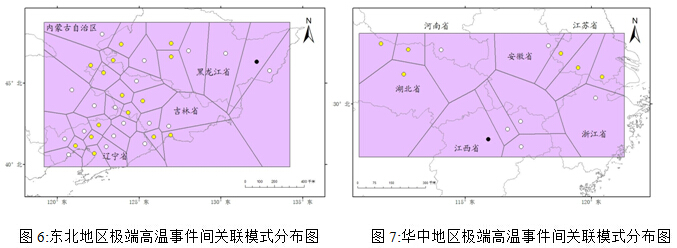
(Fig.6 extreme high temperature association patterns distribution in Northeast region)
(Fig.7extreme high temperature association patterns distribution in Central region)
② 空间邻近关系
同一条关联规则所涉及的台站在空间上具有邻近关系,各台站大多是与和自己直接相邻的台站具有最强的关联关系,所得结果符合地理学第一定律;
空间上存在强关联的台站其距离一般较近。经过分析发现,同一关联规则所涉及的站点中,最远的一组出现在黑龙江(佳木斯、虎林—>宝清),佳木斯和虎林相距约250千米,而其他组同一关联规则涉及到的关联台站之间的距离都在200千米以内;不同组关联规则间则要么彼此有公共站点,要么空间分布上相距甚远。
③ 关联规则存在双向性
很大一部分台站既有作为前件也有作为后件出现,极端高温事件中约有45%,极端低温事件中有33%,由于关联规则存在双向性,即会有AB->C,AC->B的现象同时出现,因此在空间方位上无明显规律。
④ 发生频率差异性
关联分析结果所得规则中,以极端高温事件为主,其空间关联性非常强,设置支持度为7%时,置信度高达100%的有25组,95%以上的多达65组;而极端低温事件关联的频率则远小于极端高温事件,如设置支持度为6,置信度为95%,可挖掘出的极端低温事件的关联规则仅有9组。
4. 总结
本文结合传统数据挖掘技术与地理空间分析方法,针对全国历年的气象数据主要做了如下工作:①对全国700多个气象台站1961年~2005年的气温数据进行预处理,设计了合适的极端气温事件提取方法,统计出极端气温事件发生的时间和空间信息并予以可视化,分析其时空分布规律;②将传统的空间关联规则挖掘方法与地理学分析方法有效结合先识别出极端气温事件数据集中存在的关联模式,然后再利用地理空间分析方法探究了这些关联模式内部的空间分布,空间距离,空间邻近等规律。获得了极端气温事件关联规则发生的空间分布规律及空间距离关系等,对研究我国极端气温事件发生规律、做出预警和防控决策,有一定的参考价值。
参考文献:
[1]孙凤华,杨素英,袁建等编.东北气候变化与极端气象事件[M].气象出版社.2008.3.
[2]钱维宏.气候变化与中国极端气候事件图集[M].气象出版社.2011.03
[3]魏凤英.现代气候统计诊断与预测技术[M].气象出版社.2007.05
[4]封国林.极端气候事件的检测、诊断与可预测性研究[M].科学出版社.2012.01
[5]丁裕国,江志红.极端气候研究方法导论[M].气象出版社.2009
[6]张雪伍,苏奋振,石忆邵等.空间关联规则挖掘进展[J].地理科学进展.2007.11
[7]杨萍,侯威,封国林.中国极端气候事件的群发性规律研究[J].气候与环境研究.2010.07
[8]Solon S, Q in Dahe, Manning M et al. Climate Change 2007: The Scientific Basis Contribution of Working Croup I to the Fourth Assessment Report of the Intergovernmental Panel on Climate Change[R].Cambridge. CambridgeUniversity Press,2007.
[9]姜德娟,李志,王昆.1961-2008年山东省极端降水事件的变化趋势分析[J].地理科学.2011.9
[10]张立伟,宋春英,延军平.秦岭南北年极端气象的时空变换趋势研究[J].地理科学.2011.8
[11]郑祚芳.北京极端气温变化特征及其对城市化的响应[J].地理科学.2011.04
[12]佘敦先,夏军,张永勇等.近50年来淮河流域极端降水的时空变化及统计特征[J].地理学报.2011.9
[13]张利平,杜鸿,夏军等.气候变化下极端水文事件的研究进展[J].地理科学进展.2011.11
[14]王海军,张勃,赵传燕.中国北方近57年气温时空变化特征[J].地理科学进展.2009.07
[15]任国玉,封国林,严中伟.中国极端气候变化观测研究回顾与展望[J].气候与环境研究.2010.7
[16]李尚锋,廉毅,陈圣波等.姚耀显.东北初夏极端低温事件的空间分布特征及其成因机理分析[J].地理科学.2012.06
[17]K Koperski, J Han.Discovery of spatial association rules in geographic information databases.Lecture Notes In Computer Science[J].1995, 951:47-66.
[18]王劲峰等.空间分析[M].科学出版社.2006
[19]阎永慧.空间数据挖掘中数据预处理技术探讨[C].数字测绘与GIS技术应用研讨会交流会论文集.2008.10
[20]李德仁,王树良,李德毅等.论空间数据挖掘和知识发现的理论与方法[J].武汉大学学报(信息科学版).2002(6)
[21]王占全.基于地理信息系统空间数据挖掘若干关键技术的研究[D].浙江大学
[22]Han J.,KoperskiK.,andSterfanovicN.GeoMiner:a system prototyper for spatial data mining(System prototype demonstration)[C].In Proc.1997 ACM-SIGMOD Int.Conf.Management of Data,SIGMOD'97,Tucson,AZ,May1997,553-556
[23]马荣华,马晓东,蒲英霞.从GIS数据库中挖掘空间关联规则研究[J].遥感学报.2005.11
[24]秦昆,李振宇,杜鹅.基于概念分析的空间数据挖掘研究进展[J].地球信息科学学报.2009.2
[25]陈江平,黄非,王荣等.一种基于概念格的空间关联规则挖掘算法研究[R].第六届全国地图学与GIS学术会议
[26]万幼.K邻近空间关系下的离群点检测和关联模式挖掘研究[D].武汉大学
[27]陈江平,黄炳坚.数据空间自相关性对关联规则的挖掘与实验分析[J].地球信息科学学报.2011.2
[28]韩家炜.范明,孟小峰译.数据挖掘概念与技术[M].2001年08月.机械工业出版社
[29]Pang-Ning Tan,Michael Steinbach,Vipin Kumar. 范明 范宏建译.数据挖掘导论[M]. 2006-5.人民邮电出版社
[30]王新宇,杜孝平,谢昆青.Fp_growth算法的实现方法研究[J].计算机工程与应用.2004-9
[31]李德仁, 王树良, 李德毅.空间数据挖掘理论与应用[M].2006.科学出版社 [32]FransCoenen.http://www.csc.liv.ac.uk/~frans/KDD/Software/FPgrowth/fpGrowth.html.[CP].英国利物浦大学.2003.
作者简介:
艾贝贝(1992-),女,陕西人,武汉大学本科在读,
赵雯华(1992-),女,安徽人,武汉大学本科在读,E-mai
声明:中国勘测联合网登载此文出于传递更多信息之目的,并不意味着赞同其观点或证实其描述,文章内容仅供参考。



